Protein Structure Classification and Loop Modeling Using Multiple Ramachandran Distributions
Abstract
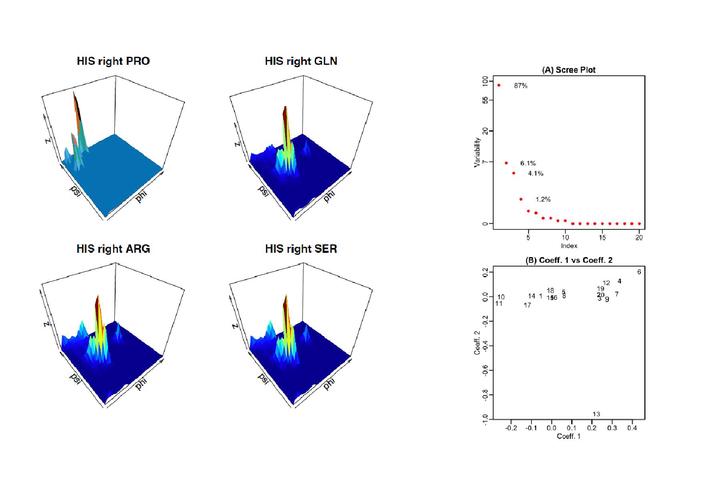
© 2017 The Authors Recently, the study of protein structures using angular representations has attracted much attention among structural biologists. The main challenge is how to efficiently model the continuous conformational space of the protein structures based on the differences and similarities between different Ramachandran plots. Despite the presence of statistical methods for modeling angular data of proteins, there is still a substantial need for more sophisticated and faster statistical tools to model the large-scale circular datasets. To address this need, we have developed a nonparametric method for collective estimation of multiple bivariate density functions for a collection of populations of protein backbone angles. The proposed method takes into account the circular nature of the angular data using trigonometric spline which is more efficient compared to existing methods. This collective density estimation approach is widely applicable when there is a need to estimate multiple density functions from different populations with common features. Moreover, the coefficients of adaptive basis expansion for the fitted densities provide a low-dimensional representation that is useful for visualization, clustering, and classification of the densities. The proposed method provides a novel and unique perspective to two important and challenging problems in protein structure research: structure-based protein classification and angular-sampling-based protein loop structure prediction.